
RabbitMQ jest znakomitym projektem open-source, pozwala na dostarczanie setek tysięcy wiadomości na sekundę do aplikacji, szybko i skutecznie. Poniższy wpis prezentuje sposób w jaki można postawić klaster RabbitMQ złożony z trzech oddzielnych hostów. W tym celu użyjemy Dockera, a do gotowego klastra podłączymy się przy pomocy Node.js.
Wstęp
RabbitMQ to system kolejkowy oparty o protokół AMQP, sam system napisany został w Erlangu. Dzięki wykorzystaniu tego języka, RabbitMQ znakomicie nadaje się do wykorzystania jako centralna szyna danych w architekturze mikroserwisów. Taka szyna zapewnia świetne podłoże dla aplikacji pozwalając na duży zakres dynamiki rozwoju w paradygmacie DDD oraz CQRS. Skoro szyna danych (kolejka wiadomości) jest kręgosłupem architektury, ważne jest aby była zawsze dostępna i odporna na awarie. Naturalnym wyborem staje się wtedy architektura redundantna, czyli replikacja danych na oddzielne węzły wykonawcze.
Replikacja w RabbitMQ wspierana jest natywnie w trybie master-slave. Oznacza to, że RabbitMQ dla każdej stworzonej kolejki wybierze zawsze jeden węzeł który jest główny i do niego będzie przekierowywał wszystkie wiadomości w celu zapisu, a także z niego pobierał wiadomości w celu odczytu z kolejki, pozostałe węzły (slave) pełnią rolę replikatora danych gotowego w każdym momencie przejąć rolę węzła master. Choć największy sens replikacja ma wtedy gdy węzły rozproszone są na różnych fizycznie maszynach, ja w tym przypadku posłużę się przykładem replikacji w ramach tej samej maszyny. RabbitMQ z racji swojego przeznaczenia - czyli setek tysięcy obsługiwanych wiadomości na sekundę, nie jest preferowany w trybie replikacji na maszynach które nie znajdują się w tej samej szafie serwerowej. Wynika to z faktu, że wiaodmości przebywają w kolejce bardzo krótko i założenia nie powinny wyjść poza pamięć RAM, replikowanie ich w oparciu o połączenie sieciowe w innej części data center lub do zupełnie innego data center oznaczałoby drastyczne spadki wydajności, a na to w systemie tej klasy nie można sobie pozwolić. Ponadto, umieszczając węzły RabbitMQ blisko siebie minimalizujemy ryzyko wystąpienia tzw. network partition (co jest bardzo mało prawdopodobne w przypadku jednego racka) czyli zjawiska polegającego na przerwaniu łączności pomiędzy węzłami w taki sposób że przynajmniej 2 węzły spośród całego klastra uznają siebie za mastera. Więcej o network partition w kontekście RabbitMQ można przeczytać tutaj.
Dlatego zasada oparta na praktyce to stawianie RabbitMQ w trybie replikacji tylko w tym samym data center.
Pobranie obrazów Dockera
Zakładam, że wiesz co to jest Docker i jak się z niego korzysta, gdyż w dalszej części wpisu będziemy szeroko z niego korzystać.
Na początek zacznijmy od pobrania odpowiednich obrazów RabbitMQ (wraz z pluginem panelu administracyjnego) oraz Node.js, do tego celu uzyjemy komend:
docker pull 3.6.6-management
docker pull node:11.10.1Uruchomienie hostów
Dla celów prezentacji uruchomimy jeden obraz RabbitMQ do którego podłączymy się komendą docker exec i wywołamy powłokę bash aby móc uruchomić konfigurację na nasz sposób. Użyjmy komendy:
docker run --hostname rabbit --name rabbit --rm -ti --net="host" rabbitmq:3.6.6-management /bin/bashPowyższa komenda spowoduje uruchomienie obrazu z RabbitMQ który zostanie usunięty po opuszczeniu powłoki. Instancja będzie podłączona do naszego interfejsu sieciowego więc nie musimy się martwić o przekierowanie portów. Jeżeli naszym oczom ukazał się shell root@rabbit:/# to znaczy że wszystko się udało.
Kolejnym krokiem jest uruchomienie trzech procesów RabbitMQ na oddzielnych portach, każdy z procesów otrzyma unikalną nazwę.
RABBITMQ_NODE_PORT=5672 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15672}]" RABBITMQ_NODENAME=rabbit rabbitmq-server -detached
RABBITMQ_NODE_PORT=5673 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15673}]" RABBITMQ_NODENAME=hare rabbitmq-server -detached
RABBITMQ_NODE_PORT=5674 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15674}]" RABBITMQ_NODENAME=john rabbitmq-server -detachedNastępnie przy pomocy komenty rabbitmqctl dołączamy oba węzły do głównego o nazwie rabbit:
rabbitmqctl -n hare stop_app
rabbitmqctl -n hare join_cluster rabbit@`hostname -s`
rabbitmqctl -n hare start_app
rabbitmqctl -n john stop_app
rabbitmqctl -n john join_cluster rabbit@`hostname -s`
rabbitmqctl -n john start_appPo wszystkim możemy otworzyć przeglądarkę i wpisać adres http://localhost:15672 w celu weryfikacji czy wszystko przebiegło pomyślnie, konsola zarządzania klastrem powinna wskazywać wszystkie węzły jak na zrucie ekranu poniżej.
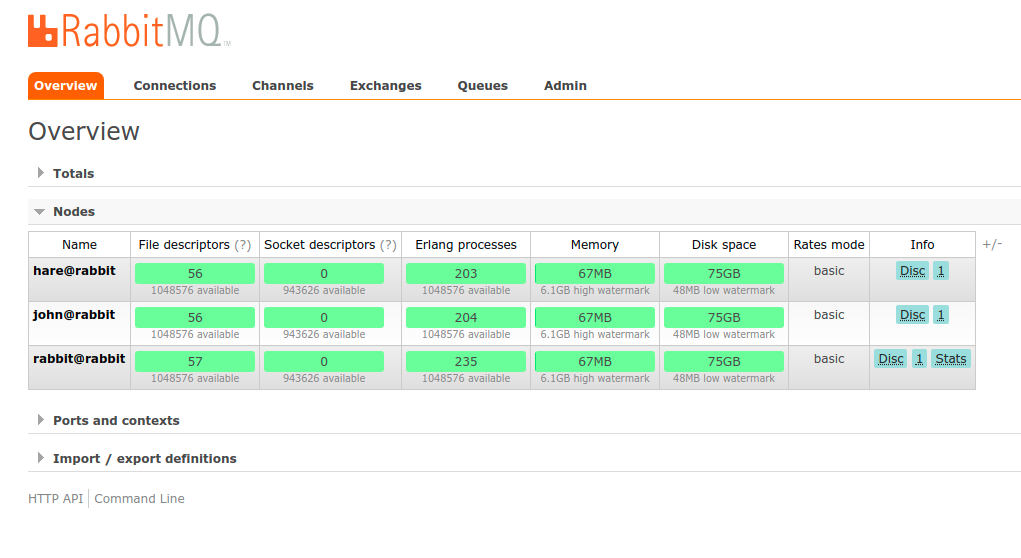
Ważne. Nie należy wyłączać shella kontenera z RabbitMQ gdyż to spowoduje jego usunięcie (opcja --rm w komendzie uruchomieniowej Dockera)
Została ostatnia rzecz do wykonania, pomimo, że klaster RabbitMQ mamy gotowy, należy jeszcze skonfigurować odpowiednie polityki. Funkcja ta realizowana jest przy pomocy panelu administracyjnego, więcej o wysokiej dostępności (HA) w RabbitMQ można przeczytać w dokumentacji.
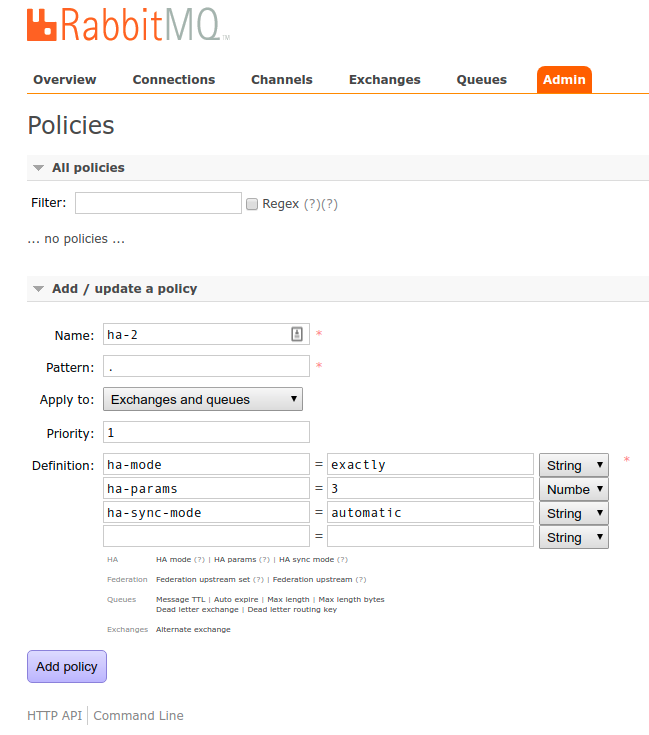
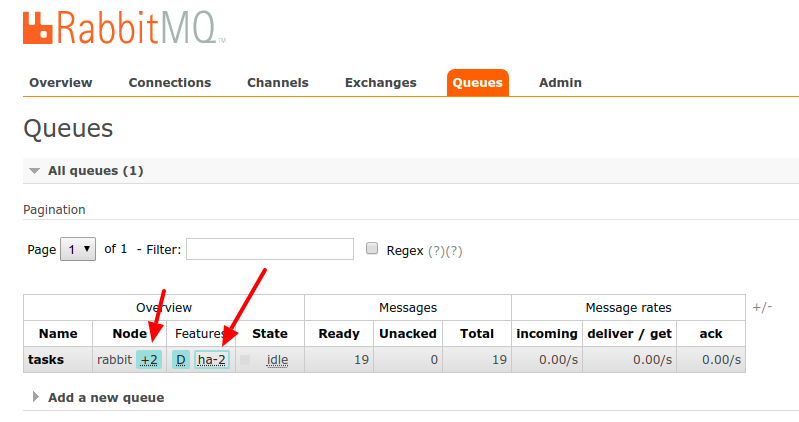
Powyżej przykład konfiguracji polityki HA. A poniżej sposób weryfikacji. Liczba +2 przy nazwie węzła oznacza ilość osobnych hostów na który kolejka jest replikowana.
Instalacja i pobranie biblioteki amqp w Node.js
Kolejnym krokiem jest uruchomienie instancji kontenera Dockera z obrazem Node.js, w tym celu należy uruchomić poniższą komendę która także współdzieli interfejs sieciowy.
docker run -ti --rm --net="host" node:11.10.1 /bin/bashNastępnie w wybranym przez nasz miejscu miejscu (np. /home) tworzymy katalog w którym umieścimy potrzebne skrypty i instalujemy bibliotekę amqp-connection-manager która pozwala na połączenie z RabbitMQ (lub innym systemem implementującym protokół AMQP) z poziomu Node.js.
npm install --save amqp-connection-managerPonadto biblioteka pozwala na dodanie kilku adresów hosta RabbitMQ zapewniając mechanizm ponownego łączenia w przypadku awarii któregoś z hostów. Jest to bardzo przydatna funkcjonalność, gdyż dba a prawidłowe połączenie z RabbitMQ a w przypadku awarii potrafi zcacheować wiadomości w pamięci do czasu pojawienia się połączenia spowrotem.
Przykładowy kod producent-konsument
Teraz kiedy mamy przygotowane wszystkie komponenty, możemy zacząć tworzyć prosty kod odpowiadający za tworzenie i odbieranie wiadomości. W tym celu stworzymy dwa pliki oraz wypełnimy je kodem.
producer.js - skrypt podłącza się do instancji RabbitMQ oraz rozpoczyna wysyłanie 10 wiadomości na sekundę.
let q = 'tasks';
let amqp = require('amqp-connection-manager');
function sleep(ms) {
if(ms <= 0){
return
}
return new Promise(resolve => setTimeout(resolve, ms));
}
let main = async () => {
var connection = amqp.connect([
'amqp://localhost:5672',
'amqp://localhost:5673',
'amqp://localhost:5674',
]);
var channelWrapper = connection.createChannel({
json: true,
setup: function(channel) {
return channel.assertQueue(q, { durable: true });
}
});
console.log('Starting message stream')
while (true) {
await channelWrapper.sendToQueue(q, { value: Math.random() })
await sleep(100)
}
}
main()consumer.js - skrypt podłącza się do instancji RabbitMQ oraz rozpoczyna odczytywanie wiadomości z kolejki.
let q = 'tasks';
let amqp = require('amqp-connection-manager');
let main = async () => {
var connection = amqp.connect([
'amqp://localhost:5672',
'amqp://localhost:5673',
'amqp://localhost:5674',
]);
var channelWrapper = connection.createChannel({
json: true,
setup: function(channel) {
return channel.assertQueue(q, { durable: true });
}
});
channelWrapper.addSetup(function(channel) {
return Promise.all([
channel.consume(q, (msg) => {
console.log(msg.content.toString())
}, {noAck: true , exclusive: false })
])
});
}
main()Tak stworzone pliki możemy uruchomić oddzielnie za pomocą Node.js i obserować jak consumer.js odbiera dane wyprodukowane przez producer.js. W celu weryfikacji działania replikacji w klastrze RabbitMQ zachęcam do wyłączenia w trakcie wymiany danych przez skrypty jednego z procesów RabbitMQ aby zaobserować w jaki sposób awaria zostanie obsłużona i w jaki sposób RabbitMQ samodzielnie wybierze nowego mastera i przekieruje odpowiednio wiadomości.
rabbitmqctl -n john stop_appWyłączenie jednej z instancji RabbitMQ nie wpływa w żadnym stopniu na produkcję i pobieranie wiadomości. Kolejki są automatycznie replikowane a połączenie odzyskiwane bez potrzeby implementacji własnych mechanizmów.
Podsumowując, RabbitMQ to świetny system kolejkowy zapewniający wysoką dostępność po odpowiedniej konfiguracji która nie przysparza wiele problemów. Duża ilość bibliotek w wielu językach np. Node.js, PHP, Java, Python, Golang, C/C++ pozwala na łatwe wdrożenie systemu w projekcie. Polecam wszystkim zapoznanie się z dokumentacją która wyjaśnia bardzo dobitnie kwestie związane z działaniem systemu oraz jego prawidłową konfiguracją, która jest naprawdę obszerna.
Cały kod znajdziesz w repozytorium na Github